COVID-19 Study Analysis#
Notes
The dataset analyzed in this study was obtained from Olink’s MGH COVID-19 study site [1]. The primary objective was to create informative visualizations that effectively highlight the dataset’s key characteristics.
To enhance clarity and readability, most code cells have been collapsed. Simply expand the drop-down sections to view the underlying code.
1. Exploratory Data Analysis#
This section of the report provides an overview of the preliminary data analysis procedures. The steps involved include loading the dataset, followed by a thorough inspection of its structure to assess key characteristics such as data types, missing values, and overall organization.
Show code cell source
patient_df <- read.delim("/Users/jennylee/Downloads/MGH_Olink_COVID_Apr_27_2021/MGH_COVID_Clinical_Info.txt", header=TRUE, sep=";")
head(patient_df)
print(paste0("This dataframe has ", nrow(patient_df), " rows in total."))
glimpse(patient_df)
| subject_id | COVID | Age_cat | BMI_cat | HEART | LUNG | KIDNEY | DIABETES | HTN | IMMUNO | ⋯ | crp_3_cat | ddimer_3_cat | ldh_3_cat | abs_neut_7_cat | abs_lymph_7_cat | abs_mono_7_cat | creat_7_cat | crp_7_cat | ddimer_7_cat | ldh_7_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | ⋯ | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | |
| 1 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | 1 | 1 | 1 | NA | NA | NA | NA | NA | NA | NA |
| 2 | 2 | 1 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | 2 | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 3 | 3 | 1 | 3 | 4 | 0 | 1 | 0 | 0 | 0 | 0 | ⋯ | 3 | 2 | 3 | NA | NA | NA | NA | NA | NA | NA |
| 4 | 4 | 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | 2 | 2 | 3 | NA | NA | NA | NA | NA | NA | NA |
| 5 | 5 | 1 | 3 | 3 | 0 | 0 | 0 | 1 | 1 | 0 | ⋯ | 5 | 3 | NA | 3 | 5 | 3 | 1 | 4 | 4 | 3 |
| 6 | 6 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ⋯ | 4 | 3 | 5 | 3 | 3 | 2 | 1 | 4 | 5 | 5 |
[1] "This dataframe has 384 rows in total."
Rows: 384
Columns: 44
$ subject_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,…
$ COVID <int> 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, …
$ Age_cat <int> 1, 2, 3, 1, 3, 1, 2, 4, 5, 2, 3, 2, 4, 4, 4, 3, 3, 2, …
$ BMI_cat <int> 4, 2, 4, 2, 3, 1, 2, 3, 2, 2, 2, 4, 4, 3, 2, 3, 1, 2, …
$ HEART <int> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, …
$ LUNG <int> 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, …
$ KIDNEY <int> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, …
$ DIABETES <int> 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, …
$ HTN <int> 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, …
$ IMMUNO <int> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, …
$ Resp_Symp <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, …
$ Fever_Sympt <int> 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, …
$ GI_Symp <int> 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, …
$ D0_draw <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ D3_draw <int> 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, …
$ D7_draw <int> 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, …
$ DE_draw <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, …
$ Acuity_0 <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 5, 2, 3, 3, 2, 2, 4, 4, …
$ Acuity_3 <int> 4, 3, 3, 3, 3, 3, 3, 3, 3, 4, 5, 2, 3, 2, 2, 2, 4, 4, …
$ Acuity_7 <int> 5, 5, 5, 5, 3, 3, 5, 5, 5, 5, 5, 2, 5, 2, 2, 3, 5, 5, …
$ Acuity_28 <int> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 2, 1, 5, 5, 5, …
$ Acuity_max <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 2, 3, 2, 1, 2, 4, 4, …
$ abs_neut_0_cat <int> 3, 3, 3, 2, 3, 3, 3, 5, 3, 1, 3, 3, 2, 3, 5, 4, 3, 3, …
$ abs_lymph_0_cat <int> 2, 3, 3, 2, 5, 2, 2, 1, 2, 3, 3, 2, 3, 1, 1, 4, 3, 4, …
$ abs_mono_0_cat <int> 2, 3, 2, 2, 3, 1, 3, 4, 3, 2, 2, 2, 3, 2, 5, 3, 2, 1, …
$ creat_0_cat <int> 2, 2, 2, 2, 2, 2, 2, 2, 5, 1, 2, 1, 2, 4, 2, 3, 2, 1, …
$ crp_0_cat <int> 1, 3, 4, 1, 4, 3, 5, 2, 3, 1, NA, 5, 1, 4, 5, 1, 3, 2,…
$ ddimer_0_cat <int> 1, 2, 3, 2, 3, 3, 3, 3, 4, 1, NA, 2, 3, 3, 3, 4, 2, 2,…
$ ldh_0_cat <int> 2, 2, 4, 2, 3, 4, 3, 2, 5, 2, NA, 5, 2, 2, 3, 5, 4, 3,…
$ Trop_72h <int> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, …
$ abs_neut_3_cat <int> 2, 2, 3, 3, 3, 3, 3, 3, 2, 2, NA, 4, 2, 2, 5, 3, 3, 2,…
$ abs_lymph_3_cat <int> 4, 4, 4, 4, 5, 4, 2, 3, 2, 3, NA, 1, 4, 2, 2, 1, 3, 4,…
$ abs_mono_3_cat <int> 2, 3, 3, 2, 2, 1, 2, 3, 2, 2, NA, 2, 3, 2, 2, 2, 3, 3,…
$ creat_3_cat <int> 1, 1, 2, 1, 1, 1, 2, 2, 3, 1, NA, 3, 1, 4, 1, 2, 1, 1,…
$ crp_3_cat <int> 1, 2, 3, 2, 5, 4, 4, 3, 3, NA, NA, 4, NA, 4, 3, NA, 3,…
$ ddimer_3_cat <int> 1, NA, 2, 2, 3, 3, 3, 2, 3, NA, NA, 4, NA, 2, 3, NA, 3…
$ ldh_3_cat <int> 1, NA, 3, 3, NA, 5, 3, 1, 2, NA, NA, 4, NA, 2, 2, NA, …
$ abs_neut_7_cat <int> NA, NA, NA, NA, 3, 3, NA, NA, NA, NA, NA, 3, NA, 2, 5,…
$ abs_lymph_7_cat <int> NA, NA, NA, NA, 5, 3, NA, NA, NA, NA, NA, 3, NA, 1, 2,…
$ abs_mono_7_cat <int> NA, NA, NA, NA, 3, 2, NA, NA, NA, NA, NA, 3, NA, 2, 5,…
$ creat_7_cat <int> NA, NA, NA, NA, 1, 1, NA, NA, NA, NA, NA, 3, NA, 4, 1,…
$ crp_7_cat <int> NA, NA, NA, NA, 4, 4, NA, NA, NA, NA, NA, NA, NA, 1, N…
$ ddimer_7_cat <int> NA, NA, NA, NA, 4, 5, NA, NA, NA, NA, NA, 4, NA, 2, 4,…
$ ldh_7_cat <int> NA, NA, NA, NA, 3, 5, NA, NA, NA, NA, NA, 3, NA, 3, NA…
Show code cell source
protein_df <- read.delim("/Users/jennylee/Downloads/MGH_Olink_COVID_Apr_27_2021/MGH_COVID_OLINK_NPX.txt", header=TRUE, sep=";")
head(protein_df)
print(paste0("This dataframe has ", nrow(protein_df), " rows in total."))
glimpse(protein_df)
| SampleID | subject_id | Timepoint | Index | OlinkID | UniProt | Assay | MissingFreq | Panel | Panel_Lot_Nr | PlateID | QC_Warning | Assay_Warning | Normalization | LOD | NPX | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <int> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <chr> | <chr> | <chr> | <chr> | <chr> | <chr> | <dbl> | <dbl> | |
| 1 | 1_D0 | 1 | D0 | 56 | OID21311 | Q9BTE6 | AARSD1 | 0.0000 | Oncology | B04404 | 20200772_Plate5 | PASS | PASS | Intensity | -1.0810 | 1.9024 |
| 2 | 1_D0 | 1 | D0 | 56 | OID20921 | Q96IU4 | ABHD14B | 0.0000 | Neurology | B04406 | 20200772_Plate5 | PASS | PASS | Intensity | -1.4574 | -0.2625 |
| 3 | 1_D0 | 1 | D0 | 56 | OID21280 | P00519 | ABL1 | 0.0013 | Oncology | B04404 | 20200772_Plate5 | PASS | PASS | Intensity | -2.4697 | 0.2659 |
| 4 | 1_D0 | 1 | D0 | 56 | OID21269 | P09110 | ACAA1 | 0.1248 | Oncology | B04404 | 20200772_Plate5 | PASS | PASS | Intensity | -0.2027 | 0.5311 |
| 5 | 1_D0 | 1 | D0 | 56 | OID20159 | P16112 | ACAN | 0.0000 | Cardiometabolic | B04405 | 20200772_Plate5 | PASS | PASS | Intensity | -3.3481 | -2.0366 |
| 6 | 1_D0 | 1 | D0 | 56 | OID20105 | Q9BYF1 | ACE2 | 0.0561 | Cardiometabolic | B04405 | 20200772_Plate5 | PASS | PASS | Intensity | -1.9055 | -1.4261 |
[1] "This dataframe has 1271808 rows in total."
Rows: 1,271,808
Columns: 16
$ SampleID <chr> "1_D0", "1_D0", "1_D0", "1_D0", "1_D0", "1_D0", "1_D0", …
$ subject_id <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ Timepoint <chr> "D0", "D0", "D0", "D0", "D0", "D0", "D0", "D0", "D0", "D…
$ Index <int> 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, …
$ OlinkID <chr> "OID21311", "OID20921", "OID21280", "OID21269", "OID2015…
$ UniProt <chr> "Q9BTE6", "Q96IU4", "P00519", "P09110", "P16112", "Q9BYF…
$ Assay <chr> "AARSD1", "ABHD14B", "ABL1", "ACAA1", "ACAN", "ACE2", "A…
$ MissingFreq <dbl> 0.0000, 0.0000, 0.0013, 0.1248, 0.0000, 0.0561, 0.8127, …
$ Panel <chr> "Oncology", "Neurology", "Oncology", "Oncology", "Cardio…
$ Panel_Lot_Nr <chr> "B04404", "B04406", "B04404", "B04404", "B04405", "B0440…
$ PlateID <chr> "20200772_Plate5", "20200772_Plate5", "20200772_Plate5",…
$ QC_Warning <chr> "PASS", "PASS", "PASS", "PASS", "PASS", "PASS", "PASS", …
$ Assay_Warning <chr> "PASS", "PASS", "PASS", "PASS", "PASS", "PASS", "PASS", …
$ Normalization <chr> "Intensity", "Intensity", "Intensity", "Intensity", "Int…
$ LOD <dbl> -1.0810, -1.4574, -2.4697, -0.2027, -3.3481, -1.9055, 0.…
$ NPX <dbl> 1.9024, -0.2625, 0.2659, 0.5311, -2.0366, -1.4261, -0.24…
1.1 Count Missing Values#
Show code cell source
count_missing_values <- function(df) {
missing_counts <- colSums(is.na(df))
missing_counts_df <- data.frame(
Column = names(missing_counts),
Missing_Count = as.numeric(missing_counts)
)
return(missing_counts_df)
}
count_missing_values(protein_df)
count_missing_values(patient_df)
| Column | Missing_Count |
|---|---|
| <chr> | <dbl> |
| SampleID | 0 |
| subject_id | 117760 |
| Timepoint | 0 |
| Index | 0 |
| OlinkID | 0 |
| UniProt | 0 |
| Assay | 0 |
| MissingFreq | 0 |
| Panel | 0 |
| Panel_Lot_Nr | 0 |
| PlateID | 0 |
| QC_Warning | 0 |
| Assay_Warning | 0 |
| Normalization | 0 |
| LOD | 0 |
| NPX | 0 |
| Column | Missing_Count |
|---|---|
| <chr> | <dbl> |
| subject_id | 0 |
| COVID | 0 |
| Age_cat | 0 |
| BMI_cat | 0 |
| HEART | 0 |
| LUNG | 0 |
| KIDNEY | 0 |
| DIABETES | 0 |
| HTN | 0 |
| IMMUNO | 0 |
| Resp_Symp | 0 |
| Fever_Sympt | 0 |
| GI_Symp | 0 |
| D0_draw | 1 |
| D3_draw | 1 |
| D7_draw | 1 |
| DE_draw | 1 |
| Acuity_0 | 0 |
| Acuity_3 | 0 |
| Acuity_7 | 0 |
| Acuity_28 | 0 |
| Acuity_max | 0 |
| abs_neut_0_cat | 4 |
| abs_lymph_0_cat | 5 |
| abs_mono_0_cat | 8 |
| creat_0_cat | 3 |
| crp_0_cat | 18 |
| ddimer_0_cat | 26 |
| ldh_0_cat | 22 |
| Trop_72h | 0 |
| abs_neut_3_cat | 106 |
| abs_lymph_3_cat | 107 |
| abs_mono_3_cat | 110 |
| creat_3_cat | 105 |
| crp_3_cat | 156 |
| ddimer_3_cat | 175 |
| ldh_3_cat | 191 |
| abs_neut_7_cat | 205 |
| abs_lymph_7_cat | 206 |
| abs_mono_7_cat | 206 |
| creat_7_cat | 193 |
| crp_7_cat | 240 |
| ddimer_7_cat | 251 |
| ldh_7_cat | 269 |
Show code cell source
rows_before_drop <- nrow(protein_df)
protein_df <- protein_df |>
filter(!is.na(subject_id))
rows_after_drop <- nrow(protein_df)
remaining_rows = rows_before_drop - rows_after_drop
print(paste0("In total, ", remaining_rows, " rows have been dropped."))
print(paste0(nrow(protein_df), " rows remain."))
[1] "In total, 117760 rows have been dropped."
[1] "1154048 rows remain."
1.2 Join the Two Data Frames#
Show code cell source
join_df <- inner_join(patient_df, protein_df, by="subject_id")
nrow(join_df)
head(join_df)
| subject_id | COVID | Age_cat | BMI_cat | HEART | LUNG | KIDNEY | DIABETES | HTN | IMMUNO | ⋯ | Assay | MissingFreq | Panel | Panel_Lot_Nr | PlateID | QC_Warning | Assay_Warning | Normalization | LOD | NPX | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | ⋯ | <chr> | <dbl> | <chr> | <chr> | <chr> | <chr> | <chr> | <chr> | <dbl> | <dbl> | |
| 1 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | AARSD1 | 0.0000 | Oncology | B04404 | 20200772_Plate5 | PASS | PASS | Intensity | -1.0810 | 1.9024 |
| 2 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | ABHD14B | 0.0000 | Neurology | B04406 | 20200772_Plate5 | PASS | PASS | Intensity | -1.4574 | -0.2625 |
| 3 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | ABL1 | 0.0013 | Oncology | B04404 | 20200772_Plate5 | PASS | PASS | Intensity | -2.4697 | 0.2659 |
| 4 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | ACAA1 | 0.1248 | Oncology | B04404 | 20200772_Plate5 | PASS | PASS | Intensity | -0.2027 | 0.5311 |
| 5 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | ACAN | 0.0000 | Cardiometabolic | B04405 | 20200772_Plate5 | PASS | PASS | Intensity | -3.3481 | -2.0366 |
| 6 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | ACE2 | 0.0561 | Cardiometabolic | B04405 | 20200772_Plate5 | PASS | PASS | Intensity | -1.9055 | -1.4261 |
1.3 Number of Unique Proteins per Patient#
Show code cell source
num_patient <- length(unique(patient_df$subject_id))
paste0("The study involves a total of ", num_patient, " unique patients.")
In this section, I will examine the relationship between the unique entries in the UniProt and Assay columns of the protein_df dataset. To gain insights into how different proteins may influence the presence of COVID, I will analyze whether significant differences exist between these two columns. This analysis aims to identify specific proteins that play a crucial role in the context of COVID presence.
Show code cell source
count_unique_entries_per_patient <- function(data, col_name) {
result <- data |>
group_by(subject_id) |>
summarise(!!paste0("unique_", col_name) := n_distinct(.data[[col_name]]))
print(paste0("Total number of unique ", col_name, " entries is: ", length(unique(result[[paste0("unique_", col_name)]]))))
return(result)
}
head(count_unique_entries_per_patient(join_df, "UniProt"))
[1] "Total number of unique UniProt entries is: 1"
| subject_id | unique_UniProt |
|---|---|
| <int> | <int> |
| 1 | 1463 |
| 2 | 1463 |
| 3 | 1463 |
| 4 | 1463 |
| 5 | 1463 |
| 6 | 1463 |
Show code cell source
head(count_unique_entries_per_patient(join_df, "Assay"))
[1] "Total number of unique Assay entries is: 1"
| subject_id | unique_Assay |
|---|---|
| <int> | <int> |
| 1 | 1463 |
| 2 | 1463 |
| 3 | 1463 |
| 4 | 1463 |
| 5 | 1463 |
| 6 | 1463 |
We can confidently state that a total of 384 patients were tested for the presence of COVID-19 virus and measured NPX levels of 1463 unique proteins. Notably, the number of unique entries identified in both the UniProt and Assay columns is equal (1493), indicating a consistent representation of proteins across these two columns.
2. Statistical Testing#
In this section, I will focus on three key aspects of the studies:
Top 10 Proteins: Analyzing the proteins that exhibit significant differences in NPX levels based on the presence of COVID-19.
Pre-existing Diseases: Investigating how certain pre-existing conditions significantly influence the presence of COVID-19.
Demographic Factors: Examining the influence of age and BMI on the presence of COVID-19.
2.1 NPX Level Variations Associated with COVID Status#
Given that there are 1493 unique proteins studied in this dataset, visualizing the differences in NPX levels for all proteins based on the presence of COVID-19 is impractical. Therefore, I will focus on identifying the top 10 proteins that demonstrate the most significant effect size using a two-sample T-test.
Effect size provides a measure of the magnitude of mean differences between the independent samples. In this context, achieving a large effect size while rejecting the null hypothesis (\(H_0\)) indicates that the NPX levels of the two groups (COVID-19 positive and negative) are significantly different. This analysis highlights the statistical significance of the differences observed and underscores the importance of these proteins in relation to COVID-19.
2.1.1 Hypothesis#
\(H_0\): There is no significant difference in the mean NPX levels of proteins between COVID-positive and COVID-negative patients.
\(H_A\): There is a significant difference in the mean NPX levels of proteins between COVID-positive and COVID-negative patients.
2.1.2 Assumptions#
To implement T-test to test our hypothesis, we must check some assumptions to ensure that our sample is suitable to be used for T-test.
Independence of Observations: The samples are independent of each other.
Normality: The data in ech group should be approximately normally distributed. Use Shapiro-Wilk normality test. Null hypothesis of Shapiro-Wilk normality test states that the groups are normally distributed.
Homogenity of Variance: The variances in two groups should be roughly equal. Use Levene’s test. Null hypothesis of Levene’s test states that the variances of the two groups compared are equal.
2.1.2.1 Checking for the homotenity of variances using Levene’s Test#
Show code cell source
join_df$COVID <- as.factor(join_df$COVID)
homogenity_results <- join_df |>
group_by(UniProt) |>
summarise(levene_test = list(leveneTest(NPX~COVID))) |>
mutate(levene_test = map(levene_test, tidy)) |>
unnest(levene_test)
homogenity_df <- data.frame(homogenity_results) |>
filter(p.value >= 0.05)
homogenity_list = homogenity_df |>
pull(UniProt)
head(homogenity_df)
print(homogenity_list)
| UniProt | statistic | p.value | df | df.residual | |
|---|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <int> | <int> | |
| 1 | A1E959 | 1.75031725 | 0.18622357 | 1 | 782 |
| 2 | A1L4H1 | 0.16795464 | 0.68204825 | 1 | 782 |
| 3 | A4D1B5 | 0.09018745 | 0.76401880 | 1 | 782 |
| 4 | A6NI73 | 2.84440403 | 0.09209144 | 1 | 782 |
| 5 | B1AKI9 | 0.80558995 | 0.36970354 | 1 | 782 |
| 6 | O00161 | 0.34160940 | 0.55907029 | 1 | 782 |
[1] "A1E959" "A1L4H1" "A4D1B5" "A6NI73"
[5] "B1AKI9" "O00161" "O00175" "O00182"
[9] "O00186" "O00214" "O00220" "O00221"
[13] "O00233" "O00241" "O00244" "O00253"
[17] "O00273" "O00292" "O00300" "O00308"
[21] "O00339" "O00399" "O00451" "O00468"
[25] "O00533" "O00548" "O00559" "O00584"
[29] "O00585" "O00592" "O00622" "O00626"
[33] "O14558" "O14579" "O14594" "O14618"
[37] "O14625" "O14662" "O14737" "O14763"
[41] "O14786" "O14788" "O14793" "O14828"
[45] "O14867" "O14904" "O14917" "O14944"
[49] "O14964" "O14974" "O15116" "O15117"
[53] "O15123" "O15169" "O15232" "O15263"
[57] "O15354" "O15357" "O15389" "O15444"
[61] "O15455" "O43155" "O43186" "O43278"
[65] "O43464" "O43505" "O43508" "O43524"
[69] "O43557" "O43561" "O43570" "O43598"
[73] "O43699" "O43707" "O43715" "O43736"
[77] "O43827" "O43895" "O43927" "O60240"
[81] "O60242" "O60462" "O60496" "O60635"
[85] "O60664" "O60763" "O60828" "O60884"
[89] "O60907" "O60934" "O75015" "O75144"
[93] "O75326" "O75354" "O75356" "O75462"
[97] "O75475" "O75493" "O75509" "O75563"
[101] "O75569" "O75629" "O75695" "O75791"
[105] "O75888" "O76036" "O76061" "O76070"
[109] "O76076" "O94760" "O94813" "O94856"
[113] "O94903" "O94907" "O94985" "O94992"
[117] "O95256" "O95379" "O95388" "O95407"
[121] "O95466" "O95498" "O95502" "O95630"
[125] "O95633" "O95644" "O95684" "O95721"
[129] "O95760" "O95817" "O95831" "O95866"
[133] "O95988" "O95994" "O95998" "O96017"
[137] "P00441" "P00519" "P00568" "P00740"
[141] "P00749" "P00750" "P00797" "P00915"
[145] "P00918" "P00995" "P01033" "P01034"
[149] "P01127" "P01130" "P01133" "P01135"
[153] "P01137" "P01138" "P01236" "P01242"
[157] "P01258" "P01275" "P01579" "P01583"
[161] "P01584" "P01589" "P01730" "P01732"
[165] "P01833" "P01903" "P02144" "P02533"
[169] "P02745" "P02749" "P02760" "P02771"
[173] "P02778" "P03950" "P03956" "P04054"
[177] "P04066" "P04080" "P04179" "P04216"
[181] "P04233" "P04626" "P04637" "P04746"
[185] "P04792" "P05089" "P05112" "P05113"
[189] "P05121" "P05164" "P05362" "P05412"
[193] "P05451" "P05455" "P05556" "P05783"
[197] "P05937" "P06127" "P06681" "P06731"
[201] "P06733" "P06748" "P06756" "P06858"
[205] "P06870" "P07108" "P07196" "P07204"
[209] "P07237" "P07306" "P07339" "P07359"
[213] "P07451" "P07478" "P07585" "P07711"
[217] "P07741" "P07858" "P07911" "P07947"
[221] "P07948" "P07949" "P08069" "P08118"
[225] "P08174" "P08236" "P08397" "P08473"
[229] "P08571" "P08581" "P08670" "P08727"
[233] "P08758" "P08833" "P08887" "P09038"
[237] "P09093" "P09104" "P09105" "P09110"
[241] "P09211" "P09237" "P09238" "P09382"
[245] "P09466" "P09496" "P09525" "P09603"
[249] "P09668" "P09758" "P09874" "P0CG37"
[253] "P10144" "P10147" "P10451" "P10586"
[257] "P10606" "P10644" "P10646" "P11215"
[261] "P11274" "P11684" "P11717" "P12034"
[265] "P12081" "P12111" "P12318" "P12429"
[269] "P12532" "P12644" "P12724" "P12830"
[273] "P12872" "P12931" "P13236" "P13385"
[277] "P13473" "P13500" "P13501" "P13598"
[281] "P13611" "P13647" "P13686" "P13688"
[285] "P13693" "P13725" "P13726" "P13747"
[289] "P13807" "P13987" "P14136" "P14174"
[293] "P14209" "P14317" "P14384" "P14543"
[297] "P14555" "P14780" "P14784" "P14868"
[301] "P15018" "P15085" "P15086" "P15090"
[305] "P15121" "P15144" "P15151" "P15260"
[309] "P15291" "P15328" "P15336" "P15509"
[313] "P15514" "P15529" "P15907" "P16112"
[317] "P16234" "P16284" "P16444" "P16455"
[321] "P17405" "P17516" "P17538" "P17676"
[325] "P17936" "P17948" "P18031" "P18065"
[329] "P18428" "P18564" "P18627" "P18827"
[333] "P19021" "P19022" "P19320" "P19429"
[337] "P19438" "P19440" "P19474" "P19801"
[341] "P19876" "P19878" "P19883" "P19957"
[345] "P19961" "P19971" "P20062" "P20160"
[349] "P20333" "P20340" "P20472" "P20711"
[353] "P20774" "P20809" "P20827" "P20936"
[357] "P21217_Q11128" "P21549" "P21583" "P21589"
[361] "P21709" "P21741" "P21810" "P21860"
[365] "P21964" "P21980" "P22004" "P22079"
[369] "P22223" "P22301" "P22304" "P22307"
[373] "P22466" "P22676" "P22692" "P22748"
[377] "P22749" "P22894" "P23141" "P23229"
[381] "P23276" "P23381" "P23515" "P23526"
[385] "P23582" "P23588" "P24001" "P24387"
[389] "P24394" "P24592" "P24821" "P25116"
[393] "P25445" "P25685" "P25774" "P25786"
[397] "P25815" "P25942" "P26440" "P26447"
[401] "P26842" "P26951" "P27352" "P27487"
[405] "P27540" "P27695" "P27930" "P28325"
[409] "P28799" "P28827" "P28838" "P28845"
[413] "P28907" "P28908" "P29279" "P29317"
[417] "P29350" "P29466" "P29475" "P29965"
[421] "P30039" "P30043" "P30044" "P30048"
[425] "P30086" "P30260" "P30519" "P30533"
[429] "P30740" "P31146" "P31431" "P31948"
[433] "P31949" "P31994" "P32456" "P32926"
[437] "P32970" "P33151" "P33241" "P34130"
[441] "P34913" "P34947" "P34949" "P34998"
[445] "P35052" "P35070" "P35218" "P35225"
[449] "P35237" "P35247" "P35318" "P35442"
[453] "P35443" "P35475" "P35590" "P35613"
[457] "P35637" "P35754" "P35916" "P35968"
[461] "P36222" "P36269" "P36941" "P36959"
[465] "P37023" "P37108" "P37173" "P37235"
[469] "P38484" "P38936" "P39060" "P39748"
[473] "P39900" "P40121" "P40189" "P40198"
[477] "P40222" "P40225" "P40259" "P40933"
[481] "P41217" "P41218" "P41222" "P41236"
[485] "P41271" "P41586" "P42331" "P42574"
[489] "P42575" "P42658" "P42701" "P42702"
[493] "P42768" "P42785" "P42830" "P42892"
[497] "P43489" "P43490" "P43628" "P43629"
[501] "P46060" "P46109" "P46379" "P47712"
[505] "P47929" "P47992" "P48023" "P48052"
[509] "P48061" "P48304" "P48307" "P48357"
[513] "P48643" "P48740" "P48745" "P48960"
[517] "P49023" "P49441" "P49747" "P49763"
[521] "P49788" "P49789" "P50225" "P50452"
[525] "P50453" "P50579" "P50583" "P50591"
[529] "P50749" "P50895" "P50995" "P51452"
[533] "P51531" "P51580" "P51671" "P51692"
[537] "P51858" "P51888" "P52564" "P52789"
[541] "P52798" "P52823" "P52888" "P53539"
[545] "P53582" "P53985" "P54317" "P54727"
[549] "P54760" "P55008" "P55039" "P55058"
[553] "P55082" "P55103" "P55145" "P55259"
[557] "P55273" "P55291" "P55773" "P55774"
[561] "P55789" "P55808" "P56159" "P57087"
[565] "P57771" "P58294" "P58499" "P58546"
[569] "P59665" "P60484" "P60568" "P61218"
[573] "P61244" "P61978" "P62166" "P62736"
[577] "P63098" "P63313" "P78310" "P78324"
[581] "P78325" "P78333" "P78380" "P78410"
[585] "P78552" "P78556" "P78560" "P80075"
[589] "P80188" "P80303" "P80370" "P80511"
[593] "P82980" "P98160" "Q00796" "Q01344"
[597] "Q01469" "Q02083" "Q02487" "Q02643"
[601] "Q02747" "Q02763" "Q02790" "Q03154"
[605] "Q03167" "Q03405" "Q03431" "Q04637"
[609] "Q04759" "Q04760" "Q04900" "Q05084"
[613] "Q05315" "Q06033" "Q06141" "Q06520"
[617] "Q06787" "Q06830" "Q07065" "Q07108"
[621] "Q07325" "Q07507" "Q07654" "Q07812"
[625] "Q07954" "Q07960" "Q08174" "Q08334"
[629] "Q08345" "Q08431" "Q08629" "Q08708"
[633] "Q10588" "Q11201" "Q12765" "Q12778"
[637] "Q12794" "Q12846" "Q12866" "Q12912"
[641] "Q12918" "Q12933" "Q12968" "Q13007"
[645] "Q13093" "Q13105" "Q13145" "Q13158"
[649] "Q13219" "Q13231" "Q13261" "Q13275"
[653] "Q13291" "Q13308" "Q13361" "Q13421"
[657] "Q13426" "Q13444" "Q13451" "Q13459"
[661] "Q13561" "Q13574" "Q13576" "Q13651"
[665] "Q13822" "Q13867" "Q14005" "Q14108"
[669] "Q14112" "Q14116" "Q14162" "Q14203"
[673] "Q14210" "Q14242" "Q14393" "Q14435"
[677] "Q14508" "Q14512" "Q14739" "Q14767"
[681] "Q14773" "Q14790" "Q15043" "Q15067"
[685] "Q15109" "Q15113" "Q15126" "Q15155"
[689] "Q15166" "Q15389" "Q15427" "Q15485"
[693] "Q15517" "Q15582" "Q15633" "Q15661"
[697] "Q15814" "Q15818" "Q15828" "Q15831"
[701] "Q15846" "Q16270" "Q16288" "Q16363"
[705] "Q16543" "Q16552" "Q16595" "Q16620"
[709] "Q16627" "Q16651" "Q16663" "Q16674"
[713] "Q16698" "Q16740" "Q16762" "Q16769"
[717] "Q16772" "Q16775" "Q16790" "Q16864"
[721] "Q16881" "Q2TAL6" "Q2VWP7" "Q496F6"
[725] "Q49AH0" "Q4KMG0" "Q4LE39" "Q53H47"
[729] "Q53H82" "Q5JTD0" "Q5JZY3" "Q5KU26"
[733] "Q5R372" "Q5T2D2" "Q5ZPR3" "Q6EIG7"
[737] "Q6FI81" "Q6GTS8" "Q6GTX8" "Q6ISS4"
[741] "Q6NW40" "Q6NXT1" "Q6P1N0" "Q6P2H3"
[745] "Q6P4E1" "Q6PGN9" "Q6PJW8" "Q6UB28"
[749] "Q6UWL2" "Q6UWN8" "Q6UX15" "Q6UX27"
[753] "Q6UX82" "Q6UXB2" "Q6UXB4" "Q6UXH1"
[757] "Q6UXH9" "Q6UXK2" "Q6WN34" "Q6XZF7"
[761] "Q6ZMC9" "Q6ZMH5" "Q6ZMJ2" "Q6ZMJ4"
[765] "Q6ZUJ8" "Q76LX8" "Q76M96" "Q7L5N7"
[769] "Q7L5Y9" "Q7L8A9" "Q7LG56" "Q7Z434"
[773] "Q7Z4W1" "Q7Z5L0" "Q7Z5R6" "Q7Z6M1"
[777] "Q7Z739" "Q7Z7D3" "Q86SF2" "Q86SR1"
[781] "Q86T13" "Q86VW0" "Q86WD7" "Q86WV1"
[785] "Q86Z14" "Q8IU57" "Q8IUN9" "Q8IW75"
[789] "Q8IWL1" "Q8IWL2" "Q8IX05" "Q8IXJ6"
[793] "Q8IYS5" "Q8N129" "Q8N149" "Q8N1Q1"
[797] "Q8N2G4" "Q8N423" "Q8N5S9" "Q8N608"
[801] "Q8N6P7" "Q8N6Q3" "Q8N8S7" "Q8NBI3"
[805] "Q8NBP7" "Q8NBS9" "Q8NBZ7" "Q8NC01"
[809] "Q8NCC3" "Q8NDB2" "Q8NEZ2" "Q8NFP4"
[813] "Q8NHJ6" "Q8NHL6" "Q8NHS0" "Q8NI22"
[817] "Q8TAD2" "Q8TCT1" "Q8TCZ2" "Q8TD06"
[821] "Q8TDL5" "Q8TDQ1" "Q8TE57" "Q8TE58"
[825] "Q8TEU8" "Q8WTT0" "Q8WTU2" "Q8WTV0"
[829] "Q8WU39" "Q8WUX2" "Q8WV07" "Q8WV92"
[833] "Q8WVQ1" "Q8WWN9" "Q8WWY7" "Q8WX77"
[837] "Q8WXI8" "Q8WYN0" "Q92484" "Q92520"
[841] "Q92583" "Q92597" "Q92609" "Q92692"
[845] "Q92820" "Q92823" "Q92832" "Q92844"
[849] "Q92851" "Q92854" "Q92917" "Q92956"
[853] "Q92982" "Q969D9" "Q969P0" "Q969V3"
[857] "Q969Z4" "Q96A56" "Q96AP7" "Q96AX2"
[861] "Q96B36" "Q96B86" "Q96CD2" "Q96D42"
[865] "Q96DU3" "Q96EK5" "Q96F46" "Q96FE7"
[869] "Q96FQ6" "Q96GW7" "Q96H15" "Q96I15"
[873] "Q96I82" "Q96IU4" "Q96J42" "Q96JA1"
[877] "Q96JP9" "Q96LA5" "Q96LC7" "Q96N03"
[881] "Q96NA2" "Q96NB1" "Q96NY8" "Q96NZ8"
[885] "Q96P31" "Q96PD2" "Q96PD4" "Q96PL1"
[889] "Q96PQ0" "Q96RD9" "Q96RJ3" "Q96SB3"
[893] "Q96SM3" "Q99426" "Q99435" "Q99497"
[897] "Q99538" "Q99549" "Q99616" "Q99674"
[901] "Q99683" "Q99685" "Q99717" "Q99727"
[905] "Q99731" "Q99795" "Q99895" "Q99969"
[909] "Q99972" "Q99983" "Q99988" "Q9BQB4"
[913] "Q9BRF8" "Q9BS26" "Q9BS40" "Q9BSW2"
[917] "Q9BT73" "Q9BU40" "Q9BUD6" "Q9BUE0"
[921] "Q9BW30" "Q9BWV1" "Q9BXJ1" "Q9BXJ7"
[925] "Q9BXS1" "Q9BXY4" "Q9BY76" "Q9BYE9"
[929] "Q9BZM5" "Q9BZR6" "Q9BZZ2" "Q9C0C4"
[933] "Q9GZM7" "Q9GZT9" "Q9GZY6" "Q9H008"
[937] "Q9H0C8" "Q9H0P0" "Q9H156" "Q9H1C3"
[941] "Q9H1U4" "Q9H2A7" "Q9H2W6" "Q9H3G5"
[945] "Q9H3R2" "Q9H3U7" "Q9H446" "Q9H4A9"
[949] "Q9H4D0" "Q9H4P4" "Q9H5V8" "Q9H5Y7"
[953] "Q9H6B4" "Q9H6S3" "Q9H773" "Q9HA65"
[957] "Q9HAN9" "Q9HAV5" "Q9HAV7" "Q9HAW4"
[961] "Q9HB29" "Q9HC38" "Q9HCB6" "Q9HCM2"
[965] "Q9HD26" "Q9NNX6" "Q9NP70" "Q9NP79"
[969] "Q9NP84" "Q9NPH0" "Q9NPH6" "Q9NPY3"
[973] "Q9NQ25" "Q9NQ30" "Q9NQ76" "Q9NQ88"
[977] "Q9NQX5" "Q9NR28" "Q9NRA1" "Q9NRD8"
[981] "Q9NRG1" "Q9NRJ3" "Q9NRM6" "Q9NRV9"
[985] "Q9NRW1" "Q9NS15" "Q9NS68" "Q9NS71"
[989] "Q9NSA1" "Q9NSK7" "Q9NUY8" "Q9NWQ8"
[993] "Q9NX58" "Q9NXA8" "Q9NY25" "Q9NYY1"
[997] "Q9NZ53" "Q9NZC2" "Q9NZD4" "Q9NZK5"
[1001] "Q9NZN5" "Q9NZQ7" "Q9NZT2" "Q9P0G3"
[1005] "Q9P0J1" "Q9P0K1" "Q9P0M4" "Q9P0V8"
[1009] "Q9P126" "Q9P1Z2" "Q9P232" "Q9UBB4"
[1013] "Q9UBP4" "Q9UBR2" "Q9UBT3" "Q9UBU3"
[1017] "Q9UBW5" "Q9UDT6" "Q9UGM5" "Q9UGT4"
[1021] "Q9UHC6" "Q9UHD0" "Q9UHD8" "Q9UHF1"
[1025] "Q9UHF4" "Q9UHV9" "Q9UIB8" "Q9UII2"
[1029] "Q9UJ68" "Q9UJU6" "Q9UJY5" "Q9UK53"
[1033] "Q9UK85" "Q9UKJ0" "Q9UKJ1" "Q9UKK9"
[1037] "Q9UKL0" "Q9UKP3" "Q9UKU9" "Q9UKX5"
[1041] "Q9ULL4" "Q9UM07" "Q9UM47" "Q9UMF0"
[1045] "Q9UMR7" "Q9UN19" "Q9UNE0" "Q9UNK0"
[1049] "Q9UNZ2" "Q9UPV0" "Q9UPY6" "Q9UQB8"
[1053] "Q9Y223" "Q9Y240" "Q9Y243" "Q9Y258"
[1057] "Q9Y265" "Q9Y266" "Q9Y275" "Q9Y279"
[1061] "Q9Y286" "Q9Y2B0" "Q9Y2V2" "Q9Y2W6"
[1065] "Q9Y2Z0" "Q9Y336" "Q9Y3D6" "Q9Y3P8"
[1069] "Q9Y478" "Q9Y4L1" "Q9Y4X3" "Q9Y5A7"
[1073] "Q9Y5C1" "Q9Y5K6" "Q9Y5K8" "Q9Y5L3"
[1077] "Q9Y5V3" "Q9Y5X1" "Q9Y624" "Q9Y653"
[1081] "Q9Y662" "Q9Y680" "Q9Y6A5" "Q9Y6D9"
[1085] "Q9Y6E0" "Q9Y6K9" "Q9Y6N7" "Q9Y6Q6"
[1089] "Q9Y6Y9"
2.1.2.2 Checking for normality using Shapiro-Wilk test#
Show code cell source
normality_results <- join_df |>
group_by(UniProt) |>
summarise(
shapiro_test = list(shapiro.test(NPX)), .groups = "drop") |>
mutate(shapiro_test = map(shapiro_test, tidy)) |>
unnest(shapiro_test)
normality_df <- data.frame(normality_results) |>
filter(p.value >= 0.05)
normality_list <- normality_df |> pull(UniProt)
head(normality_df)
print(normality_list)
| UniProt | statistic | p.value | method | |
|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <chr> | |
| 1 | O15467 | 0.9987295 | 0.86121216 | Shapiro-Wilk normality test |
| 2 | O43557 | 0.9970696 | 0.16779689 | Shapiro-Wilk normality test |
| 3 | O95544 | 0.9963716 | 0.06854867 | Shapiro-Wilk normality test |
| 4 | P00533 | 0.9970415 | 0.16198854 | Shapiro-Wilk normality test |
| 5 | P01374 | 0.9970769 | 0.16933109 | Shapiro-Wilk normality test |
| 6 | P05121 | 0.9964111 | 0.07216494 | Shapiro-Wilk normality test |
[1] "O15467" "O43557" "O95544" "P00533" "P01374" "P05121" "P08571" "P09603"
[9] "P09958" "P16562" "P18428" "P20062" "P21709" "P26951" "P27487" "P28908"
[17] "P35247" "P35813" "P35968" "P42830" "P50591" "P51671" "P52789" "P55773"
[25] "P78333" "P78552" "P80075" "Q13093" "Q13241" "Q15846" "Q6DN72" "Q6UXB2"
[33] "Q6UXH9" "Q86SR1" "Q96J42" "Q96JA1" "Q99727" "Q9GZM7" "Q9HAV7" "Q9HBB8"
[41] "Q9NP70" "Q9NZC2" "Q9UIB8" "Q9Y266" "Q9Y4X3"
Show code cell source
filter_for_proteins <- intersect(homogenity_list, normality_list)
print("The list of proteins that passed all assumptions are:")
filter_for_proteins
[1] "The list of proteins that passed all assumptions are:"
- 'O43557'
- 'P05121'
- 'P08571'
- 'P09603'
- 'P18428'
- 'P20062'
- 'P21709'
- 'P26951'
- 'P27487'
- 'P28908'
- 'P35247'
- 'P35968'
- 'P42830'
- 'P50591'
- 'P51671'
- 'P52789'
- 'P55773'
- 'P78333'
- 'P78552'
- 'P80075'
- 'Q13093'
- 'Q15846'
- 'Q6UXB2'
- 'Q6UXH9'
- 'Q86SR1'
- 'Q96J42'
- 'Q96JA1'
- 'Q99727'
- 'Q9GZM7'
- 'Q9HAV7'
- 'Q9NP70'
- 'Q9NZC2'
- 'Q9UIB8'
- 'Q9Y266'
- 'Q9Y4X3'
Show code cell source
filtered_df <- join_df |>
filter(UniProt %in% filter_for_proteins)
print(nrow(filtered_df))
print(paste0("This filtered dataset contains ", length(filter_for_proteins), " unique proteins."))
head(filtered_df)
[1] 27440
[1] "This filtered dataset contains 35 unique proteins."
| subject_id | COVID | Age_cat | BMI_cat | HEART | LUNG | KIDNEY | DIABETES | HTN | IMMUNO | ⋯ | Assay | MissingFreq | Panel | Panel_Lot_Nr | PlateID | QC_Warning | Assay_Warning | Normalization | LOD | NPX | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <fct> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | <int> | ⋯ | <chr> | <dbl> | <chr> | <chr> | <chr> | <chr> | <chr> | <chr> | <dbl> | <dbl> | |
| 1 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | AMBN | 0.0025 | Inflammation | B04403 | 20200772_Plate5 | PASS | PASS | Intensity | -0.9412 | -0.0957 |
| 2 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | CCL11 | 0.0013 | Inflammation | B04403 | 20200772_Plate5 | PASS | PASS | Intensity | -7.9432 | -3.1507 |
| 3 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | CCL23 | 0.0000 | Inflammation | B04403 | 20200772_Plate5 | PASS | PASS | Intensity | -5.5427 | -2.1460 |
| 4 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | CCL27 | 0.0013 | Cardiometabolic | B04405 | 20200772_Plate5 | PASS | PASS | Intensity | -3.1467 | -1.6989 |
| 5 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | CCL8 | 0.0000 | Oncology | B04404 | 20200772_Plate5 | PASS | PASS | Intensity | -11.1811 | -1.4358 |
| 6 | 1 | 1 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ⋯ | CD14 | 0.0000 | Cardiometabolic | B04405 | 20200772_Plate5 | PASS | PASS | Intensity | -8.3767 | -2.3645 |
2.1.3 Results and Interpretation#
Show code cell source
compute_cohens_d <- function(g1, g2) {
g1_mean <- mean(g1)
g2_mean <- mean(g2)
g1_sd <- sd(g1)
g2_sd <- sd(g2)
g1_n <- length(g1)
g2_n <- length(g2)
pooled_sd <- sqrt(((g1_n - 1) * g1_sd^2 + (g2_n - 1) * g2_sd^2) / (g1_n + g2_n - 2))
cohens_d <- (g1_mean - g2_mean) / pooled_sd
return(cohens_d)
}
compare_t_test <- function(data) {
results <- data |>
group_by(UniProt) |>
summarise(
t_test=list(t.test(NPX ~ COVID, data = cur_data())),
.groups="drop"
) |>
mutate(
p_value=map_dbl(t_test, ~ .x$p.value),
effect_size=map2_dbl(
t_test, UniProt,
~ {
g1 <- data$NPX[data$COVID == 1 & data$UniProt == .y]
g2 <- data$NPX[data$COVID == 0 & data$UniProt == .y]
compute_cohens_d(g1, g2)
}
)
)
results <- results |>
mutate(adjusted_p_value = p.adjust(p_value, method="BH")) |>
filter(adjusted_p_value < 0.05) |>
arrange(desc(effect_size))
return(results)
}
protein_t_test_df <- compare_t_test(filtered_df)
head(protein_t_test_df)
paste0("After removing non-significant relationships, ", nrow(protein_t_test_df), " proteins remain.")
Warning message:
“There was 1 warning in `summarise()`.
ℹ In argument: `t_test = list(t.test(NPX ~ COVID, data = cur_data()))`.
ℹ In group 1: `UniProt = "O43557"`.
Caused by warning:
! `cur_data()` was deprecated in dplyr 1.1.0.
ℹ Please use `pick()` instead.”
| UniProt | t_test | p_value | effect_size | adjusted_p_value |
|---|---|---|---|---|
| <chr> | <list> | <dbl> | <dbl> | <dbl> |
| P20062 | -13.0748266218357 , 107.527384283259 , 5.88318495470336e-24 , -0.874385379617813 , -0.644159113468144 , -1.68101341463415 , -0.921741168091168 , 0 , 0.0580713051502305 , two.sided , Welch Two Sample t-test, NPX by COVID | 5.883185e-24 | 1.3689743 | 2.059115e-22 |
| Q96JA1 | -12.6639839639431 , 108.487947519905 , 4.09695309378174e-23 , -1.0112248276909 , -0.737523723486917 , -1.75076829268293 , -0.876394017094017 , 0 , 0.0690441710980073 , two.sided , Welch Two Sample t-test, NPX by COVID | 4.096953e-23 | 1.3085855 | 7.169668e-22 |
| O43557 | -10.7684096452754 , 107.943764287575 , 8.35629046285534e-19 , -1.06152055195062 , -0.731476293299885 , -0.579958536585366 , 0.316539886039886 , 0 , 0.083252629882871 , two.sided , Welch Two Sample t-test, NPX by COVID | 8.356290e-19 | 1.1209872 | 9.749006e-18 |
| P80075 | -10.2349228172632 , 104.748024267567 , 1.86467000666308e-17 , -1.38107912368503 , -0.932798258011864 , -5.07111219512195 , -3.9141735042735 , 0 , 0.113038340542935 , two.sided , Welch Two Sample t-test, NPX by COVID | 1.864670e-17 | 1.1168153 | 1.631586e-16 |
| Q9GZM7 | -9.73719165102095 , 108.506639068431 , 1.7715793493603e-16 , -0.708341502172199 , -0.468739096813278 , -1.05927804878049 , -0.470737749287749 , 0 , 0.0604425095639388 , two.sided , Welch Two Sample t-test, NPX by COVID | 1.771579e-16 | 1.0059032 | 1.240106e-15 |
| Q96J42 | -7.49338924413719 , 95.4417702537119 , 3.39076894575144e-11 , -0.562930615696669 , -0.32713607181636 , -1.18369146341463 , -0.73865811965812 , 0 , 0.0593901276521445 , two.sided , Welch Two Sample t-test, NPX by COVID | 3.390769e-11 | 0.9870787 | 1.318632e-10 |
Show code cell source
top_10_proteins <- protein_t_test_df |>
slice_head(n=10) |>
pull(UniProt)
print("Top 10 proteins with largest effect size values are:")
top_10_proteins
[1] "Top 10 proteins with largest effect size values are:"
- 'P20062'
- 'Q96JA1'
- 'O43557'
- 'P80075'
- 'Q9GZM7'
- 'Q96J42'
- 'P18428'
- 'Q9HAV7'
- 'P05121'
- 'P08571'
Show code cell source
options(repr.plot.width = 12, repr.plot.height = 12)
visualize_top_10_proteins <- join_df |>
filter(UniProt %in% top_10_proteins) |>
ggplot(aes(x=COVID, y=NPX, fill=factor(COVID))) +
geom_boxplot() +
labs(title="NPX Levels by Protein and COVID Status",
x="COVID Status",
y="NPX",
caption = "Figure 1. Protein Expression Variation Associated with COVID Presence"
) + facet_wrap(~UniProt, scales = "free") +
theme_bw() +
theme(
plot.title=element_text(hjust = 0.5),
plot.caption=element_text(hjust = 0.5, size=12, colour = "darkgrey"))
visualize_top_10_proteins

2.2 Impact of Pre-Existing Health Conditions on COVID Presence#
To analyze the relationship between pre-existing health conditions and the presence of COVID-19, I am utilizing a binomial generalized linear model (GLM). This model is well suited to the task because the dependent variable, COVID, is binary, indicating whether an individual tests positive (1) or negative (0) for COVID-19.
The model assesses the individual impact of five pre-existing conditions: heart disease, lung disease, kidney disease, diabetes, and hypertension. I have chosen a non-interaction model, which assumes that these conditions have independent, additive effects on the likelihood of testing positive for COVID-19. This allows me to observe how each condition contributes to the presence of COVID-19 without accounting for any combined or interactive effects between the conditions at this stage.
My primary objective is to determine which, if any, of these conditions are significantly associated with COVID-19 presence and to identify the condition with the strongest relationship to the outcome.
2.2.1 Hypothesis#
\(H_0\): Pre-existing health conditions (heart disease, lung disease, kidney disease, diabetes, hypertension) have a significant impact on the presence of COVID-19.
\(H_1\): Pre-existing health conditions has a significant impact on the presence of COVID-19.
Show code cell source
pre_existing_conds = c("HEART", "LUNG", "KIDNEY", "DIABETES", "HTN", "IMMUNO", "COVID")
pre_existing_df <- join_df |>
select(all_of(pre_existing_conds))
for (column in pre_existing_conds) {
pre_existing_df[[column]] <- factor(pre_existing_df[[column]])
}
head(pre_existing_df)
str(pre_existing_df)
| HEART | LUNG | KIDNEY | DIABETES | HTN | IMMUNO | COVID | |
|---|---|---|---|---|---|---|---|
| <fct> | <fct> | <fct> | <fct> | <fct> | <fct> | <fct> | |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
'data.frame': 1154048 obs. of 7 variables:
$ HEART : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ LUNG : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ KIDNEY : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ DIABETES: Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ HTN : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ IMMUNO : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ COVID : Factor w/ 2 levels "0","1": 2 2 2 2 2 2 2 2 2 2 ...
Show code cell source
compare_pre_existing_conds <- glm(COVID ~ HEART + LUNG + KIDNEY + DIABETES + HTN + IMMUNO,
data = pre_existing_df,
family = binomial
)
pre_existing_summary <- summary(compare_pre_existing_conds)
print(pre_existing_summary)
pre_existing_summary_df <- data.frame(
Condition = rownames(pre_existing_summary$coefficients),
Estimate = pre_existing_summary$coefficients[, "Estimate"],
STD = pre_existing_summary$coefficients[, "Std. Error"],
Z_value = pre_existing_summary$coefficients[, "z value"],
p_value = pre_existing_summary$coefficients[, "Pr(>|z|)"]
)
pre_existing_summary_df |>
filter(p_value < 0.05)
Call:
glm(formula = COVID ~ HEART + LUNG + KIDNEY + DIABETES + HTN +
IMMUNO, family = binomial, data = pre_existing_df)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.081029 0.006337 486.20 <2e-16 ***
HEART1 -0.279085 0.007991 -34.93 <2e-16 ***
LUNG1 -1.385784 0.006756 -205.11 <2e-16 ***
KIDNEY1 -0.258386 0.008078 -31.99 <2e-16 ***
DIABETES1 0.424673 0.006998 60.68 <2e-16 ***
HTN1 -0.572461 0.007527 -76.05 <2e-16 ***
IMMUNO1 -1.171622 0.008357 -140.20 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 773343 on 1154047 degrees of freedom
Residual deviance: 688212 on 1154041 degrees of freedom
AIC: 688226
Number of Fisher Scoring iterations: 5
| Condition | Estimate | STD | Z_value | p_value | |
|---|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <dbl> | <dbl> | |
| (Intercept) | (Intercept) | 3.0810290 | 0.006336893 | 486.20502 | 0.000000e+00 |
| HEART1 | HEART1 | -0.2790854 | 0.007990581 | -34.92680 | 2.914718e-267 |
| LUNG1 | LUNG1 | -1.3857840 | 0.006756234 | -205.11188 | 0.000000e+00 |
| KIDNEY1 | KIDNEY1 | -0.2583860 | 0.008078190 | -31.98563 | 1.727527e-224 |
| DIABETES1 | DIABETES1 | 0.4246733 | 0.006998466 | 60.68091 | 0.000000e+00 |
| HTN1 | HTN1 | -0.5724614 | 0.007527214 | -76.05224 | 0.000000e+00 |
| IMMUNO1 | IMMUNO1 | -1.1716219 | 0.008356871 | -140.19863 | 0.000000e+00 |
2.2.2 Results and Interpretation#
Based on the results, all the pre-existing health conditions are strongly associated with the presence of COVID-19. Interestingly, only diabetes has a positive Estimate, representing the log-odds of testing positive for COVID-19 associated with having diabetes, while holding other variables constant. This suggests that individuals with diabetes are more likely to test positive for COVID-19 compared to those without diabetes, indicating that diabetes as a pre-existing condition increases the likelihood of contracting the COVID-19 virus.
Show code cell source
options(repr.plot.width = 12, repr.plot.height = 8)
pre_existing_fig <- ggplot(pre_existing_summary_df, aes(x = Condition, y = Estimate)) +
geom_bar(stat = "identity", fill = "lightblue", color="navy", alpha=0.7) +
geom_errorbar(aes(ymin = Estimate - STD, ymax = Estimate + STD), width = 0.3) +
theme_bw() +
ggtitle("Effect of Pre-Existing Conditions on COVID Presence") +
labs(
y="Log-Odds Estimate",
x="Pre-Existing Condision",
caption = "Figure 2. Log-odd estimates of various pre-existing conditions on COVID presence."
) +
coord_flip() +
theme_bw() +
theme(
plot.title=element_text(hjust = 0.5),
plot.caption=element_text(hjust = 0.5, size=12, colour = "darkgrey"))
pre_existing_fig
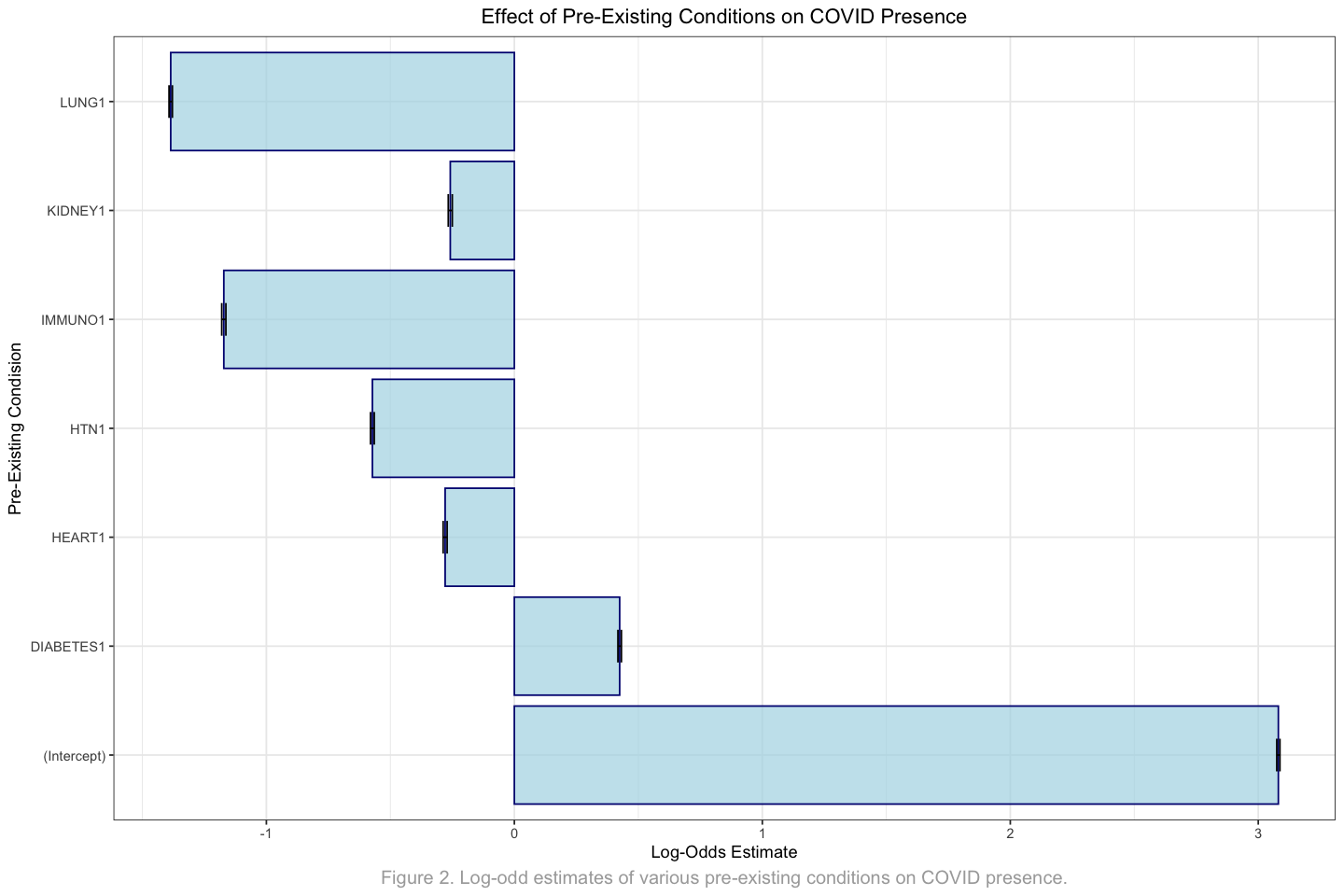
As seen from the above, lung disease has the strongest association with testing positive for COVID-19. This indicates that having lung diease is most strongly associated with a reduced likelihood of COVID-19 presence.
2.3 Influence of Age and BMI on COVID-19 Risk#
Before statistically analyzing the influence of Age and BMI on the presence of COVID-19, I will visualize the differences in mean percentages of COVID-19 occurrence across the various categories of both Age and BMI. This visualization will help illustrate how these factors relate to the likelihood of contracting COVID-19.
Show code cell source
age_df <- join_df |>
group_by(Age_cat) |>
summarise(
total_cases = n(),
covid_positive = sum(COVID == 1),
covid_percentage = (covid_positive / total_cases) * 100
)
bmi_df <- join_df |>
group_by(BMI_cat) |>
summarise(
total_cases = n(),
covid_positive = sum(COVID == 1),
covid_percentage = (covid_positive / total_cases) * 100
)
age_df
bmi_df
| Age_cat | total_cases | covid_positive | covid_percentage |
|---|---|---|---|
| <int> | <int> | <int> | <dbl> |
| 1 | 88320 | 82432 | 93.33333 |
| 2 | 216384 | 206080 | 95.23810 |
| 3 | 338560 | 306176 | 90.43478 |
| 4 | 315008 | 262016 | 83.17757 |
| 5 | 195776 | 176640 | 90.22556 |
| BMI_cat | total_cases | covid_positive | covid_percentage |
|---|---|---|---|
| <int> | <int> | <int> | <dbl> |
| 0 | 16192 | 8832 | 54.54545 |
| 1 | 203136 | 156032 | 76.81159 |
| 2 | 409216 | 391552 | 95.68345 |
| 3 | 341504 | 310592 | 90.94828 |
| 4 | 141312 | 128064 | 90.62500 |
| 5 | 42688 | 38272 | 89.65517 |
Show code cell source
options(repr.plot.width = 12, repr.plot.height = 6)
age_fig <- ggplot(age_df, aes(x = Age_cat, y = covid_percentage)) +
geom_bar(stat = "identity", position = "dodge", fill="lightgreen", color="black", alpha=0.7) +
theme_bw() +
ggtitle("Percentage of COVID Positive Cases by Age Category") +
xlab("Age Category") +
ylab("Percentage of COVID Positive Cases") +
theme(
plot.title = element_text(hjust = 0.5),
axis.text.x = element_text(angle = 45, hjust = 1)
)
bmi_fig <- ggplot(bmi_df, aes(x = BMI_cat, y = covid_percentage)) +
geom_bar(stat = "identity", position = "dodge", fill="lightpink", color="black", alpha=0.7) +
theme_bw() +
ggtitle("Percentage of COVID Positive Cases by BMI Category") +
xlab("BMI Category") +
ylab("Percentage of COVID Positive Cases") +
theme(
plot.title = element_text(hjust = 0.5),
axis.text.x = element_text(angle = 45, hjust = 1)
)
age_bmi_fig <- plot_grid(age_fig, bmi_fig, ncol=2)
age_bmi_fig
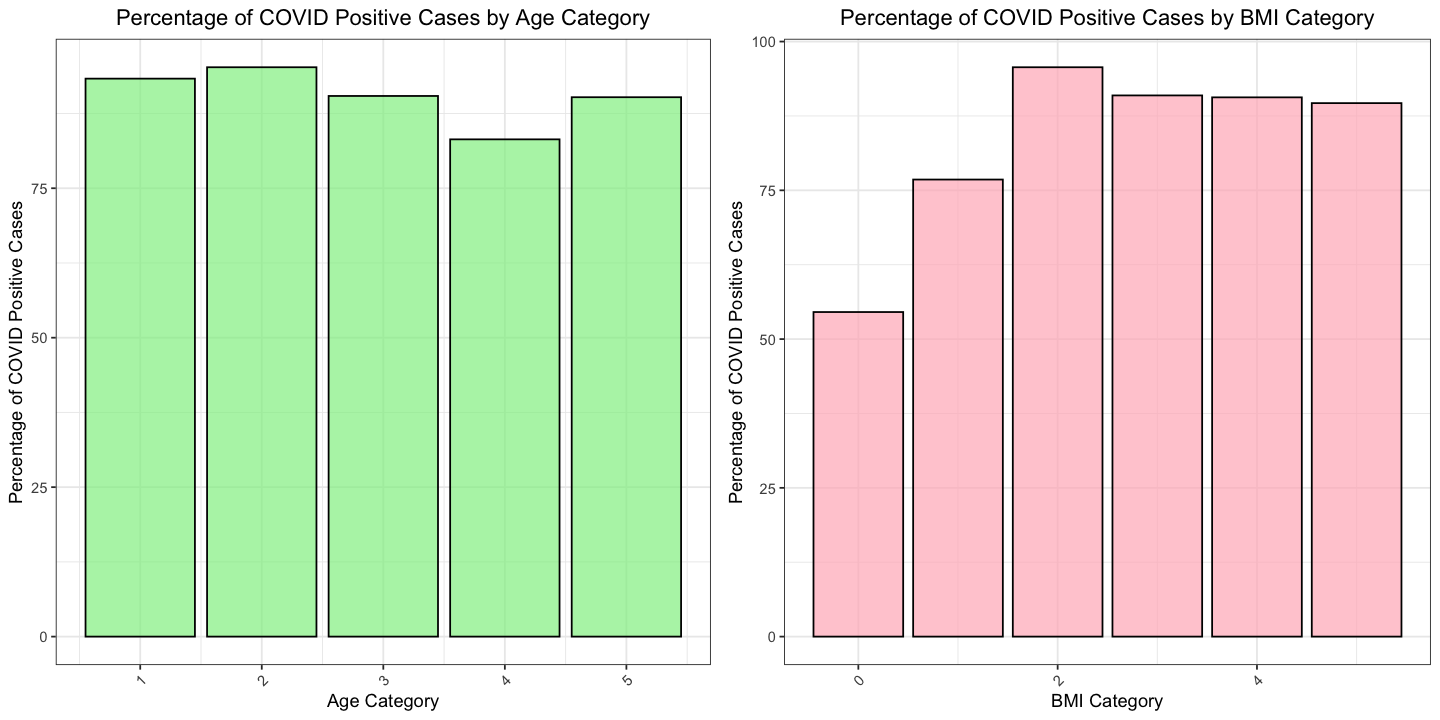
The visualization above reveals that, for Age, the likelihood of contracting COVID-19 remains relatively consistent across different age groups. In contrast, the visualization suggests that higher BMI values may be associated with an increased probability of testing positive for the COVID-19 virus.
To further investigate these relationships, we will conduct a Chi-Square test to assess the independence of COVID-19 presence across the various age and BMI categories. This statistical test will help determine if the observed differences in COVID-19 rates among these groups are statistically significant.
Chi-Square test is the ideal choice of modelling for the task as it specializes in determining association between categorical variables.
2.3.1 Hypothesis#
\(H_0\): There is no significant association between the presence of COVID-19 and the age group (or BMI category).
\(H_1\): There is a significant association between the presence of COVID-19 and the age group (or BMI category).
Show code cell source
options(repr.plot.width = 8, repr.plot.height = 6)
determine_statistical_relationship <- function(data, col_name) {
print(paste("Chi-Square Test Results for", col_name))
contingency_table <- table(data[[col_name]], data[["COVID"]])
chi2_test <- chisq.test(contingency_table)
result_df <- data.frame(
Chi2 = chi2_test$statistic,
DF = chi2_test$parameter,
p_value = chi2_test$p.value
)
fig <- ggplot(data, aes_string(x = col_name)) +
geom_bar(position = "dodge", fill="salmon", colour="black", alpha=0.5) +
labs(title = paste0("Association between ", col_name, " and ", " COVID"),
y = "Count") +
theme_bw() +
theme(plot.title = element_text(hjust = 0.5),
axis.text.x = element_text(angle = 45, hjust = 1)
)
print(fig)
return(result_df)
}
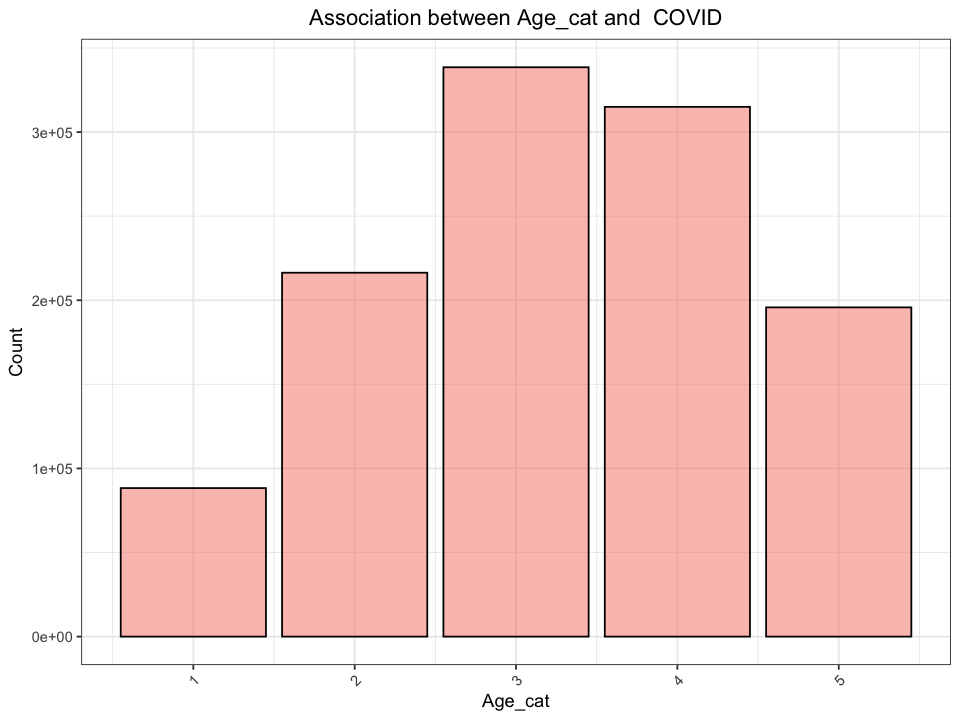
determine_statistical_relationship(join_df, "Age_cat")
[1] "Chi-Square Test Results for Age_cat"
Warning message:
“`aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.”
| Chi2 | DF | p_value | |
|---|---|---|---|
| <dbl> | <int> | <dbl> | |
| X-squared | 22862.47 | 4 | 0 |
determine_statistical_relationship(join_df, "BMI_cat")
[1] "Chi-Square Test Results for BMI_cat"
| Chi2 | DF | p_value | |
|---|---|---|---|
| <dbl> | <int> | <dbl> | |
| X-squared | 73707.03 | 5 | 0 |
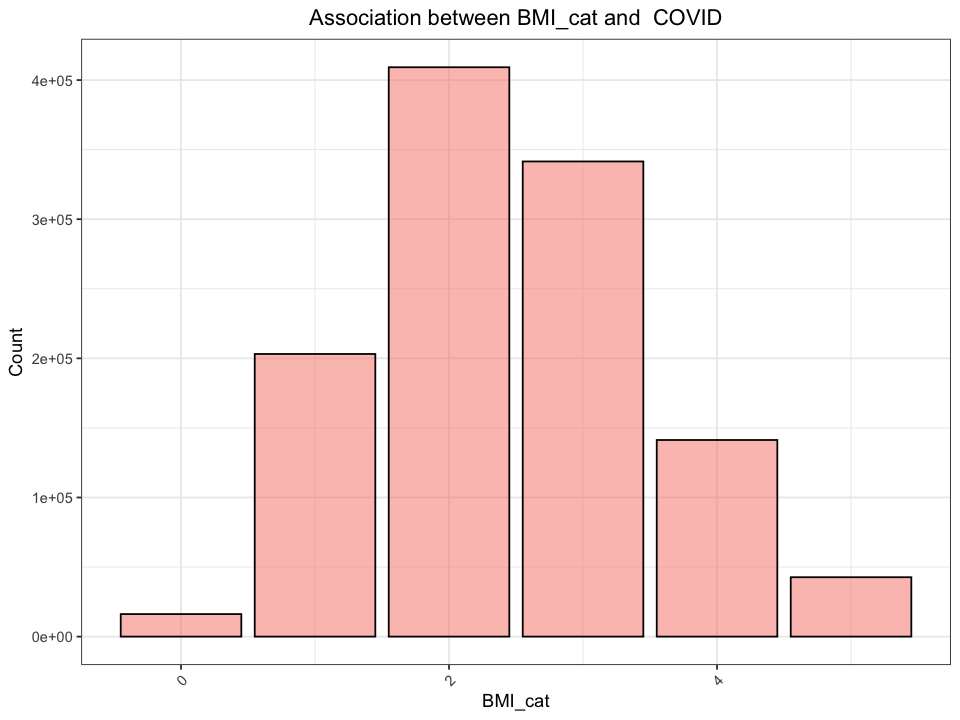
2.3.2 Results and Interpretation#
Since the \(p\)-values from both Chi-Square tests are below the significance level of \(a\) = \(0.05\), we conclude that there are statistically significant associations between age groups and BMI categories with the presence of COVID-19. This indicates that the likelihood of contracting COVID-19 varies significantly across different age groups and BMI categories.